Rakuda is a ranking of Japanese Large Language Models based on how well they answer a set of open-ended questions in Japanese about Japanese topics. We hope that Rakuda can help stimulate the development of open-source models that perform well in Japanese, in the spirit of English-language leaderboards like Huggingface's human_eval_llm. For a detailed explanation of how Rakuda works, please check out the accompanying blog post, and for the full code implementation check out the project on github.
In brief, we ask the AI Assistants in the ranking to answer a set of 40 open-ended questions. We then show pairs of these answers to GPT-4 and ask it to choose which model gave a better answer. Based on GPT-4's preferences, we estimate the underlying Bradley-Terry strength of each model in a Bayesian fashion. Bradley-Terry strengths are optimal versions of Elo scores.
Please contact us if you have any suggestions or requests for models that you'd like us to add to this ranking!
| Rank | Model | Strength | Stronger than the next model at confidence level |
|---|---|---|---|
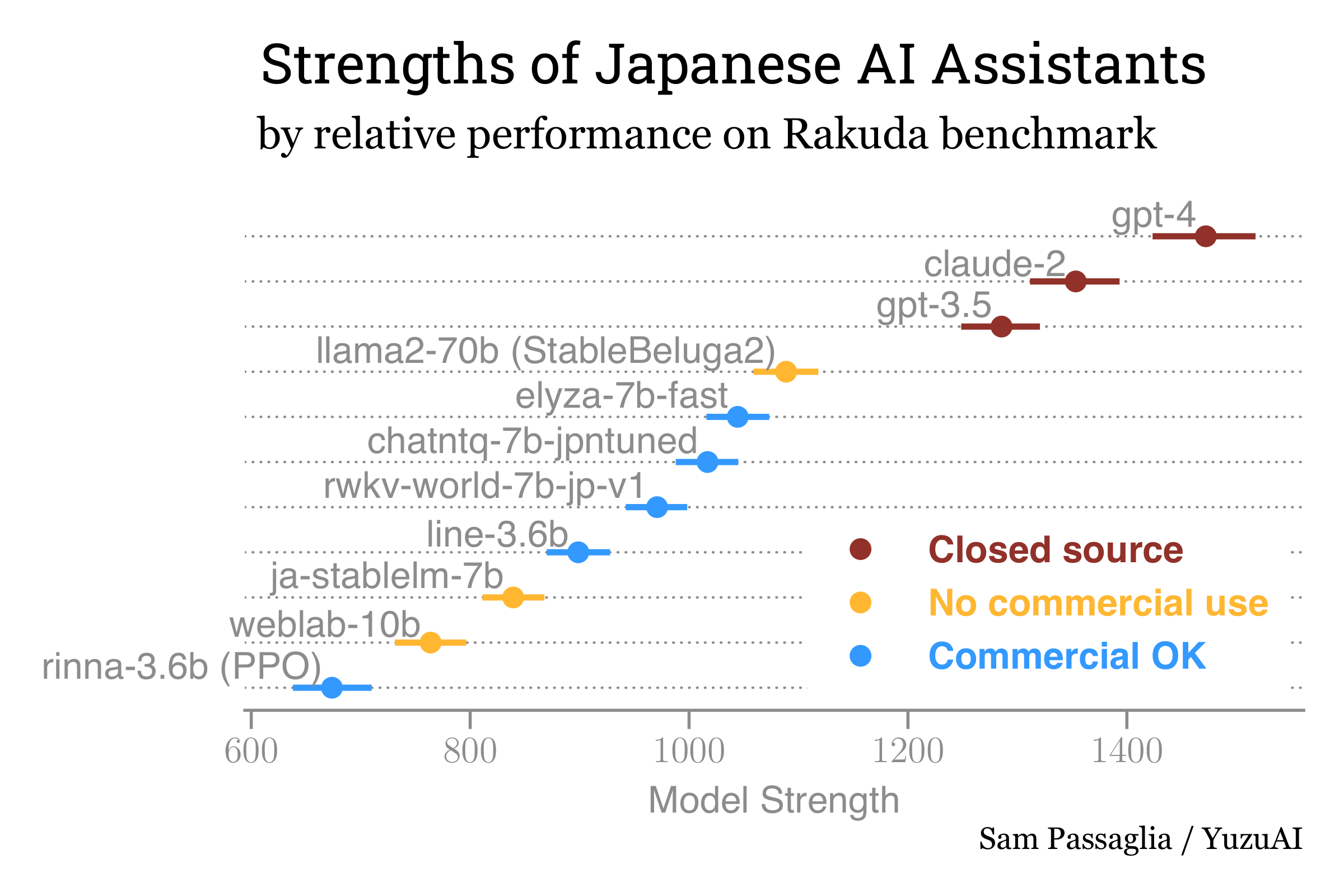
| 1 | gpt-4 | 1472 ± 49 | 97.5% |
| 2 | claude-2 | 1353 ± 42 | 89.3% |
| 3 | gpt-3.5 | 1285 ± 37 | 100.0% |
| 4 | llama2-70b (StableBeluga2) | 1089 ± 30 | 85.8% |
| 5 | elyza-7b-fast | 1044 ± 29 | 75.0% |
| 6 | chatntq-7b-jpntuned | 1017 ± 29 | 50.9% |
| 7 | elyza-7b | 1016 ± 29 | 86.8% |
| 8 | rwkv-world-7b-jp-v1 | 971 ± 29 | 89.8% |
| 9 | super-trin | 921 ± 27 | 71.4% |
| 10 | line-3.6b | 899 ± 29 | 92.8% |
| 11 | ja-stablelm-7b | 839 ± 28 | 95.3% |
| 12 | weblab-10b | 764 ± 33 | 97.5% |
| 13 | rinna-3.6b (PPO) | 674 ± 36 | 66.2% |
| 14 | rinna-3.6b (SFT) | 653 ± 36 | N/A |
Date Updated: 2023-09-27